Kubernetes 多集群项目介绍
2021-11-03
为什么要使用集群联邦
Kubernetes 从 1.8 版本起就声称单集群最多可支持 5000 个节点和 15 万个 Pod,实际上应该很少有公司会部署如此庞大的一个单集群,很多情况下因为各种各样的原因我们可能会部署多个集群,但是又想将它们统一起来管理,这时候就需要用到集群联邦(Federation)。
集群联邦的一些典型应用场景:
- 高可用:在多个集群上部署应用,可以最大限度地减少集群故障带来的影响
- 避免厂商锁定:可以将应用负载分布在多个厂商的集群上并在有需要时直接迁移到其它厂商
- 故障隔离:拥有多个小集群可能比单个大集群更利于故障隔离
Federation v1
最早的多集群项目,由 K8s 社区提出和维护。
Federation v1 在 K8s v1.3 左右就已经着手设计(Design Proposal),并在后面几个版本中发布了相关的组件与命令行工具(kubefed),用于帮助使用者快速建立联邦集群,并在 v1.6 时,进入了 Beta 阶段;但 Federation v1 在进入 Beta 后,就没有更进一步的发展,由于灵活性和 API 成熟度的问题,在 K8s v1.11 左右正式被弃用。
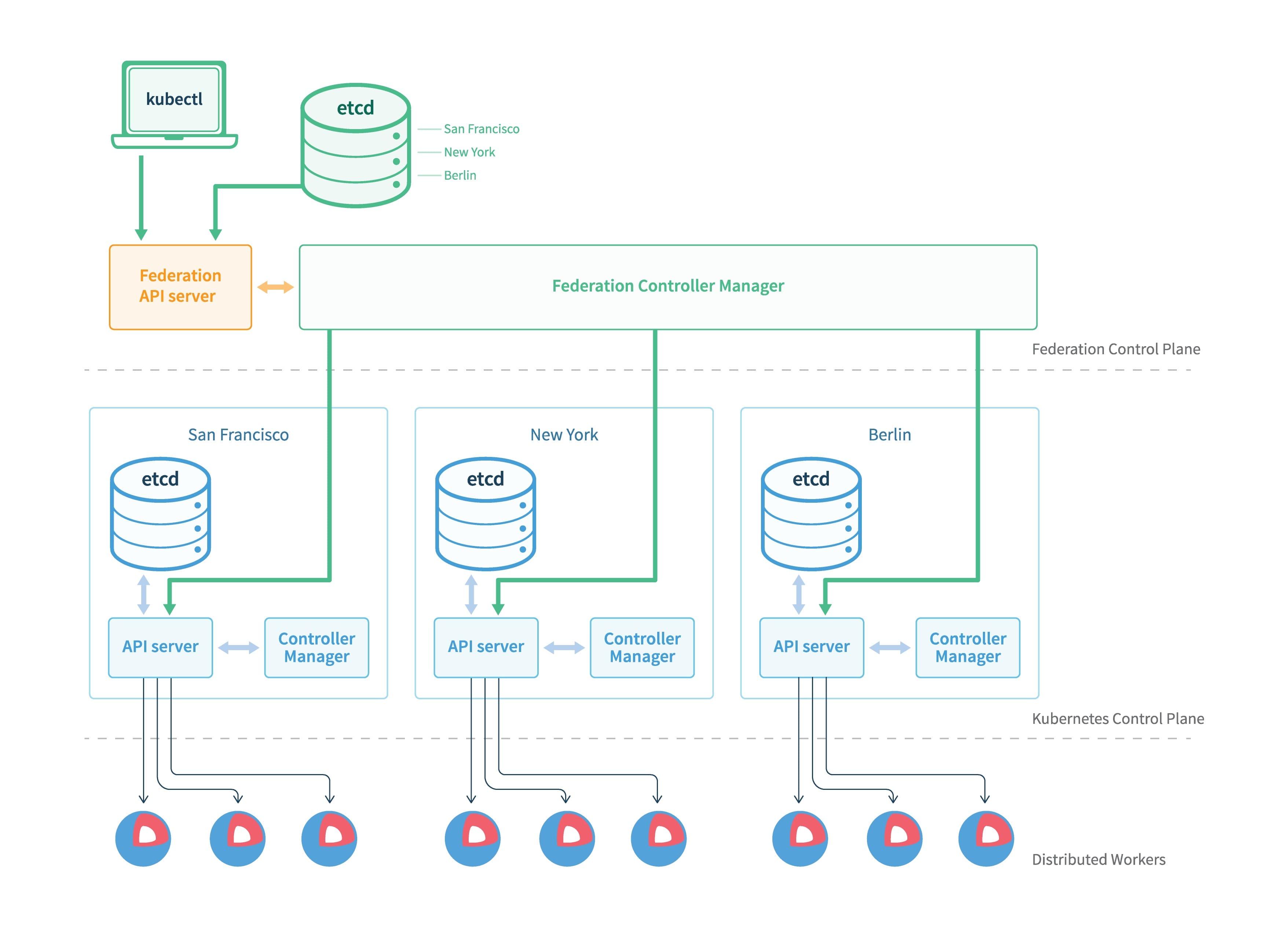
v1 的基本架构如上图,主要有三个组件:
- Federation API Server:类似 K8s API Server,对外提供统一的资源管理入口,但只允许使用 Adapter 拓展支持的 K8s 资源
- Controller Manager:提供多个集群间资源调度及状态同步,类似 kube-controller-manager
- Etcd:储存 Federation 的资源
在 v1 版本中我们要创建一个联邦资源的大致步骤如下:把联邦的所有配置信息都写到资源对象 annotations 里,整个创建流程与 K8s 类似,将资源创建到 Federation API Server,之后 Federation Controller Manager 会根据 annotations 里面的配置将该资源创建到各子集群;下面是一个 ReplicaSet 的示例:
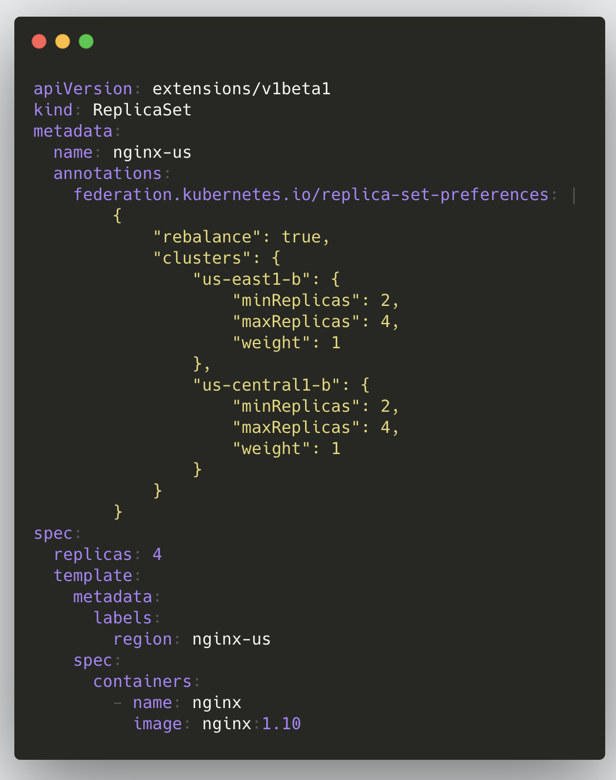
这种架构带来的主要问题有两个:
- 不够灵活,每当创建一种新资源都要新增 Adapter(提交代码再发版);并且对象会携带许多 Federation 专属的 Annotation
- 缺少独立的 API 对象版本控制,例如 Deployment 在 Kubernetes 中是 GA,但在 Federation v1 中只是 Beta
Federation v2
有了 v1 版本的经验和教训之后,社区提出了新的集群联邦架构:Federation v2;Federation 项目的演进也可以参考 Kubernetes Federation Evolution 这篇文章。
v2 版本利用 CRD 实现了整体功能,通过定义多种自定义资源(CR),从而省掉了 v1 中的 API Server;v2 版本由两个组件构成:
- admission-webhook 提供了准入控制
- controller-manager 处理自定义资源以及协调不同集群间的状态
在 v2 版本中要创建一个联邦资源的大致流程如下:
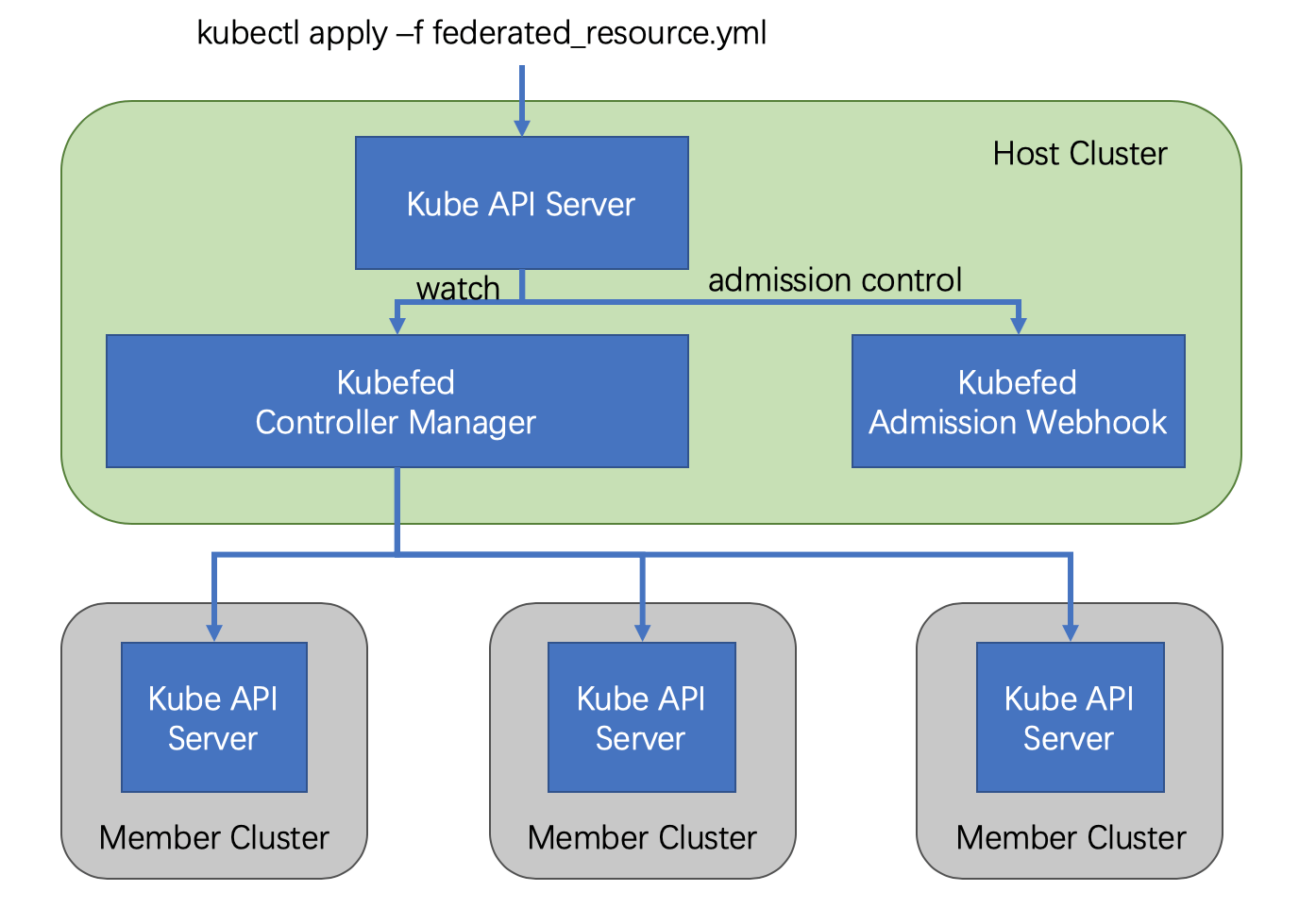
将 Federated Resource 创建到 Host 集群的 API Server 中,之后 controller-manager 会介入将相应资源分发到不同的集群,分发的规则等都写在了这个 Federated Resource 对象里面。
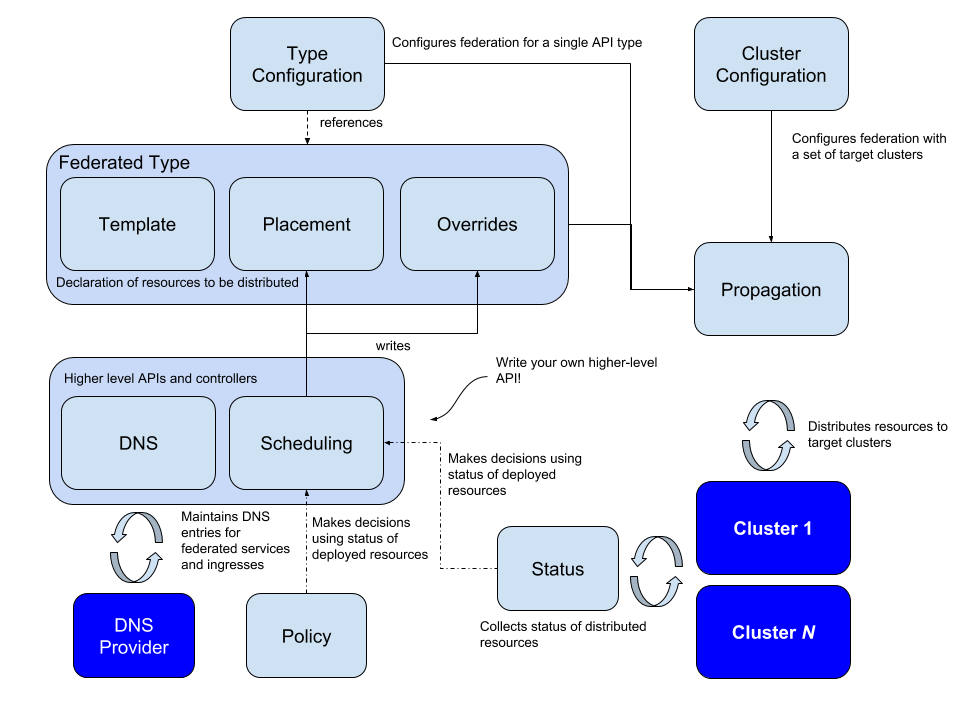
在逻辑上,Federation v2 分为两个大部分:configuration(配置)和 propagation(分发);configuration 主要包含两个配置:Cluster Configuration 和 Type Configuration。
Cluster Configuration
用来保存被联邦托管的集群的 API 认证信息,可通过 kubefedctl join/unjoin 来加入/删除集群,当成功加入时,会建立一个 KubeFedCluster CR 来存储集群相关信息,如 API Endpoint、CA Bundle 和 Token 等。后续 controller-manager 会使用这些信息来访问不同 Kubernetes 集群。
apiVersion: core.kubefed.io/v1beta1
kind: KubeFedCluster
metadata:
creationTimestamp: "2019-10-24T08:05:38Z"
generation: 1
name: cluster1
namespace: kube-federation-system
resourceVersion: "647452"
selfLink: /apis/core.kubefed.io/v1beta1/namespaces/kube-federation-system/kubefedclusters/cluster1
uid: 4c5eb57f-5ed4-4cec-89f3-cfc062492ae0
spec:
apiEndpoint: https://172.16.200.1:6443
caBundle: LS....Qo=
secretRef:
name: cluster1-shb2x
status:
conditions:
- lastProbeTime: "2019-10-28T06:25:58Z"
lastTransitionTime: "2019-10-28T05:13:47Z"
message: /healthz responded with ok
reason: ClusterReady
status: "True"
type: Ready
region: ""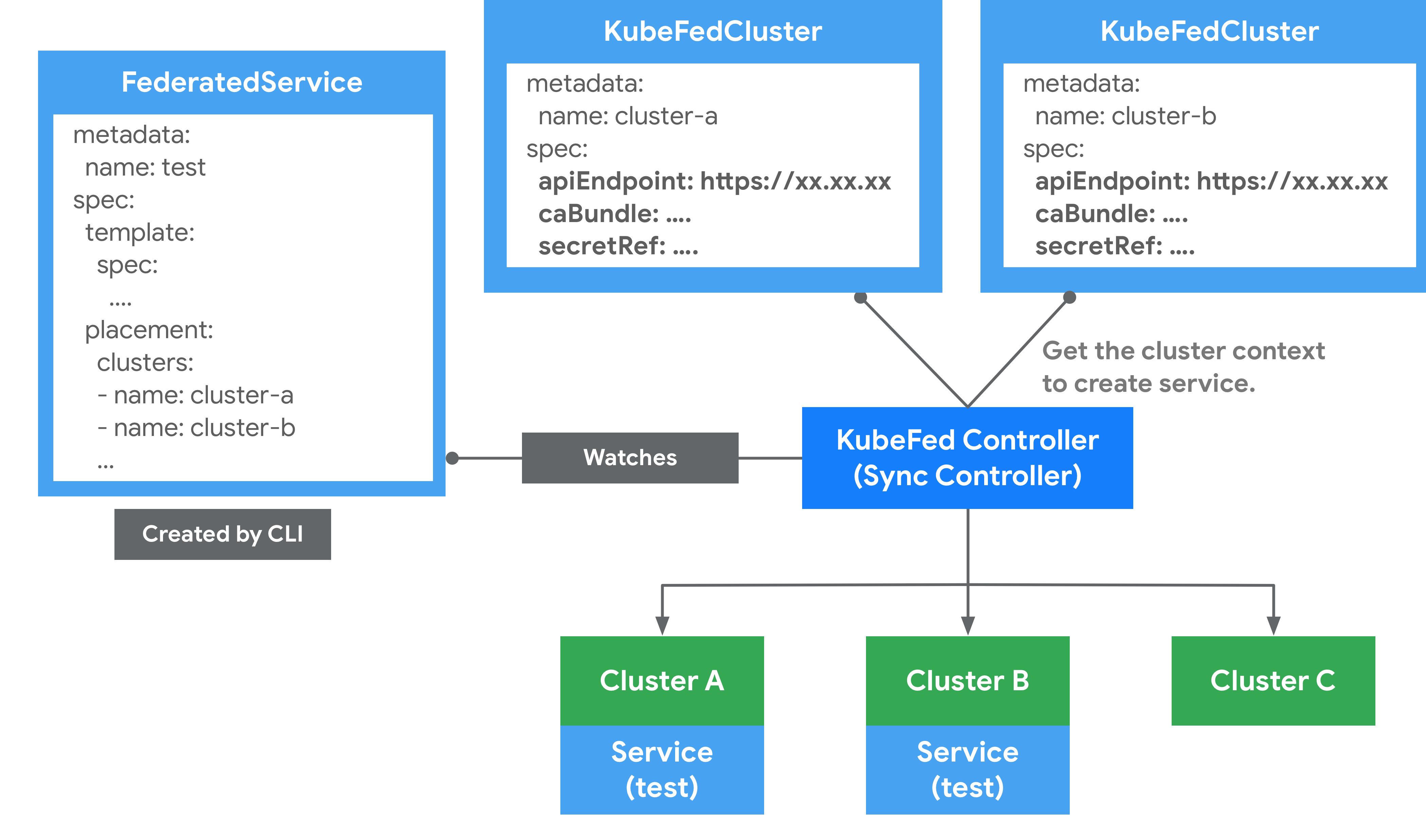
Type Configuration
定义了哪些 Kubernetes API 资源要被用于联邦管理;比如说想将 ConfigMap 资源通过联邦机制建立在不同集群上时,就必须先在 Host 集群中,通过 CRD 建立新资源 FederatedConfigMap,接着再建立名称为 configmaps 的 Type configuration(FederatedTypeConfig)资源,然后描述 ConfigMap 要被 FederatedConfigMap 所管理,这样 Kubefed controller-manager 才能知道如何建立 Federated 资源,一个示例如下:
apiVersion: core.kubefed.k8s.io/v1beta1
kind: FederatedTypeConfig
metadata:
name: configmaps
namespace: kube-federation-system
spec:
federatedType:
group: types.kubefed.k8s.io
kind: FederatedConfigMap
pluralName: federatedconfigmaps
scope: Namespaced
version: v1beta1
propagation: Enabled
targetType:
kind: ConfigMap
pluralName: configmaps
scope: Namespaced
version: v1Federated Resource CRD
其中还有一个关键的 CRD:Federated Resource,如果想新增一种要被联邦托管的资源的话,就需要建立一个新的 FederatedXX 的 CRD,用来描述对应资源的结构和分发策略(需要被分发到哪些集群上);Federated Resource CRD 主要包括三部分:
- Templates 用于描述被联邦的资源
- Placement 用来描述将被部署的集群,若没有配置,则不会分发到任何集群中
- Overrides 允许对部分集群的部分资源进行覆写
一个示例如下:
apiVersion: types.kubefed.k8s.io/v1beta1
kind: FederatedDeployment
metadata:
name: test-deployment
namespace: test-namespace
spec:
template: # 定义 Deployment 的所有內容,可理解成 Deployment 与 Pod 之间的关联。
metadata:
labels:
app: nginx
spec:
...
placement:
clusters:
- name: cluster2
- name: cluster1
overrides:
- clusterName: cluster2
clusterOverrides:
- path: spec.replicas
value: 5这些 FederatedXX CRD 可以通过 kubefedctl enable <target kubernetes API type> 来创建,也可以自己生成/编写对应的 CRD 再创建。
结合上面介绍了的 Cluster Configuration、Type Configuration 和 Federated Resource CRD,再来看 v2 版本的整体架构和相关概念就清晰很多了:
Scheduling
Kubefed 目前只能做到一些简单的集群间调度,即手工指定,对于手工指定的调度方式主要分为两部分,一是直接在资源中制定目的集群,二是通过 ReplicaSchedulingPreference 进行比例分配。
直接在资源中指定可以通过 clusters 指定一个 cluster 列表,或者通过 clusterSelector 来根据集群标签选择集群,不过有两点要注意:
- 如果
clusters字段被指定,clusterSelector将会被忽略 - 被选择的集群是平等的,该资源会在每个被选中的集群中部署一个无差别副本
spec:
placement:
clusters:
- name: cluster2
- name: cluster1
clusterSelector:
matchLabels:
foo: bar如果需要在多个集群间进行区别调度的话就需要引入 ReplicaSchedulingPreference 进行按比例的调度了:
apiVersion: scheduling.kubefed.io/v1alpha1
kind: ReplicaSchedulingPreference
metadata:
name: test-deployment
namespace: test-ns
spec:
targetKind: FederatedDeployment
totalReplicas: 9
clusters:
A:
minReplicas: 4
maxReplicas: 6
weight: 1
B:
minReplicas: 4
maxReplicas: 8
weight: 2totalReplicas 定义了总副本数,clusters 描述不同集群的最大/最小副本以及权重。
目前 ReplicaSchedulingPreference 只支持 deployments 和 replicasets 两种资源。
Karmada
Karmada 是由华为开源的多云容器编排项目,这个项目是 Kubernetes Federation v1 和 v2 的延续,一些基本概念继承自这两个版本。
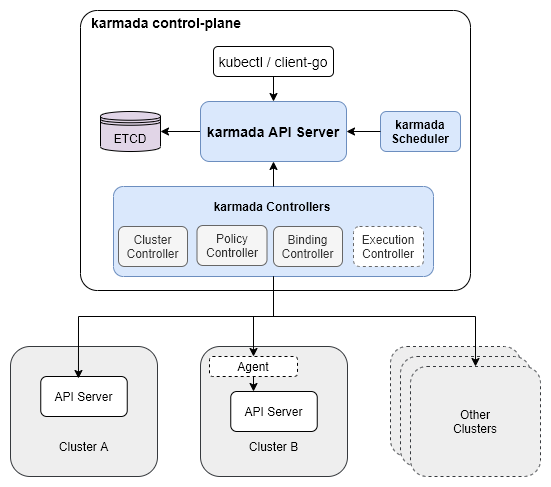
Karmada 主要有三个组件:
- Karmada API Server:本质就是一个普通的 K8s API Server,绑定了一个单独的 etcd 来存储那些要被联邦托管的资源
- Karmada Controller Manager:多个 controller 的集合,监听 Karmada API Server 中的对象并与成员集群 API server 进行通信
- Karmada Scheduler:提供高级的多集群调度策略
和 Federation v1 类似,我们下发一个资源也是要写入到 Karmada 自己的 API Server 中,之前 controller-manager 根据一些 policy 把资源下发到各个集群中;不过这个 API Server 是 K8s 原生的,所以支持任何资源,不会出现之前 Federation v1 版本中的问题,然后联邦托管资源的分发策略也是由一个单独的 CRD 来控制的,也不需要配置 v2 中的 Federated Resource CRD 和 Type Configure。
Karmada 的一些基本概念:
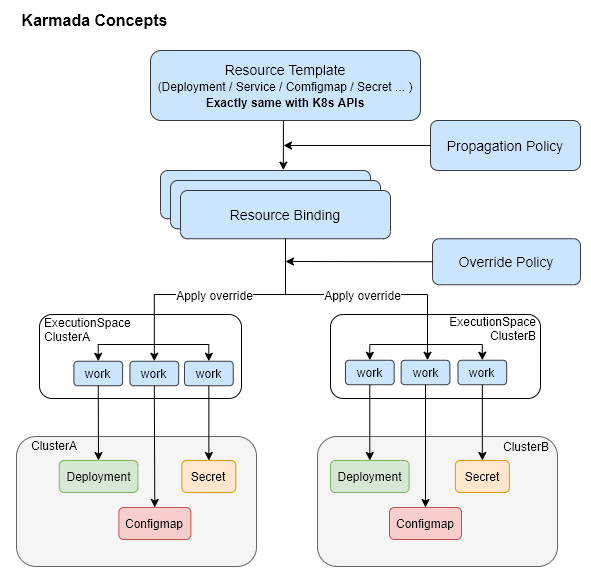
- 资源模板(Resource Template):Karmada 使用 K8s 原生 API 定义作为资源模板,便于快速对接 K8s 生态工具链
- 分发策略(Propagation Policy):Karmada 提供独立的策略 API,用来配置资源分发策略
- 差异化策略(Override Policy):Karmada 提供独立的差异化 API,用来配置与集群相关的差异化配置,比如配置不同集群使用不同的镜像
Cluster
Cluster 资源记录的内容和 Federation v2 类似,就是访问被纳管集群的一些必要信息:API Endpoint、CA Bundle 和访问 Token。
spec:
apiEndpoint: https://172.31.165.66:55428
secretRef:
name: member1
namespace: karmada-cluster
syncMode: Push但是有一个不一样的点是,Karmada 的 Cluster 资源有两种 sync 模式:Push 和 Pull;Push 就是最普通、最常见的方式,host 集群的 Karmada 组件会负责同步并更新这类集群的状态;Pull 模式的 member 集群上会运行一个 karmada-agent 组件,这个组件会负责收集自己的状态并且更新 host 集群的相应的 Cluster 资源状态。
Propagation Policy
在 Karmada 中分发资源到 member 集群需要配置这个单独 PropagationPolicy CR;以下面的 nginx 应用为例,首先是 Resource Template,这个就是普通的 K8s Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx之后配置一个 PropagationPolicy 来控制这个 nginx Deployment 资源的分发策略即可,在下面的示例中,会将 nginx 应用按 1:1 的权重比分发到 member1 和 member2 集群中:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1在 Karmada API Server 中创建这两个资源后,可以通过 Karmada API Server 查询到该资源的状态:
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 2/2 2 2 51s但是注意,这并不代表应用运行在 Karmada API Server 所在的集群上,实际上这个集群上没有任何工作负载,只是存储了这些 Resource Template,实际的工作负载都运行在上面 PropagationPolicy 配置的 member1 和 member2 集群中,切换到 member1/member2 集群中可以看到:
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 6m26s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-7cgfz 1/1 Running 0 6m29s分发策略除了上面最普通的指定集群名称外也支持 LabelSelector、FieldSelector 和 ExcludeClusters,如果这几个筛选项都设置了,那只有全部条件都满足的集群才会被筛选出来;除了集群亲和性,还支持 SpreadConstraints:对集群动态分组,按 region、zone 和 provider 等分组,可以将应用只分发到某类集群中。
针对有 replicas 的资源(比如原生的 Deployment 和 StatefulSet),支持在分发资源到不同集群的时候按要求更新这个副本数,比如 member1 集群上的 nginx 应用我希望有 2 个副本,member2 上的只希望有 1 个副本;策略有很多,首先是 ReplicaSchedulingType,有两个可选值:
Duplicated:每个候选成员集群的副本数都是一样的,从原本资源那里面复制过来的,和不设置ReplicaSchedulingStrategy的效果是一样的Divided:根据有效的候选成员集群的数量,将副本分成若干部分,每个集群的副本数由ReplicaDivisionPreference决定
而这个 ReplicaDivisionPreference 又有两个可选值:
Aggregated:在考虑集群可用资源的情况下,将这些副本调度到尽量少的集群上,如果一个集群就能容纳所有副本,那只会调度到这一个集群上,其它集群上也会存在相应的资源,不过副本数是 0Weighted:根据WeightPreference来划分副本数,这个WeightPreference就很简单了,直接指定每个集群的权重是多少
完整和详细的结构可以参考 Placement 的 API 定义。
Override Policy
Override Policy 就很简单了,通过增加 OverridePolicy 这个 CR 来配置不同集群的差异化配置,直接看一个例子:
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: example-override
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
targetCluster:
clusterNames:
- member1
labelSelector:
matchLabels:
failuredomain.kubernetes.io/region: dc1
overriders:
plaintext:
- path: /spec/template/spec/containers/0/image
operator: replace
value: 'dc-1.registry.io/nginx:1.17.0-alpine'
- path: /metadata/annotations
operator: add
value:
foo: barDemo
最后看一个 Karmada 官方的例子:
